 Na sociedade da informação, na sociedade em rede, o volume de informações estimula a demanda pelo uso de tecnologia para coleta, análise e apresentação destes conteúdos. As profissões jurídicas e o Direito não ficam imunes a este fenômeno.
Na sociedade da informação, na sociedade em rede, o volume de informações estimula a demanda pelo uso de tecnologia para coleta, análise e apresentação destes conteúdos. As profissões jurídicas e o Direito não ficam imunes a este fenômeno.
Conforme anunciado na coluna da última semana, a feira LegalTech reuniu cerca de 200 expositores para divulgação de soluções de tecnologia da informação aplicada ao campo jurídico. A feira, ainda, destacou a atualidade e a importância de conceitos como e-discovery e information governance para o campo do suporte a litígios.
Dentro do vasto espectro de softwares que foram apresentados na referida feira, acredito que minha função é tentar agrupá-los em tipos de tecnologias e metodologias para que seja possível identificar o estado da arte das soluções disponíveis para as equipes de trabalham com informação jurídica como insumo de produção.
O termo que destaco para a reflexão de hoje é Technology Assisted Review (TAR), a tecnologia para apoio à revisão dos documentos do caso.
É, ou deve ser óbvio que escritórios e gabinetes devem possuir capacidade de gerir casos ou processos sob sua responsabilidade. Mas vamos separar dois tipos de informação para serem geridas: os metadados e o conteúdo.
É mais fácil encontrarmos soluções de tecnologia da informação para a gestão dos metadado, que são os dados sobre o conteúdo: data de entrada, prazos, responsável, arquivos de peças e quantidades são gerenciados com razoável precisão pelos gabinetes e escritórios.
Já o conteúdo é mais complicado: responder perguntas sobre o que é relevante nos milhares de arquivos e páginas de peças é para poucos. Todos os documentos organizados por data que constam no texto, bem como a soma dos valores monetários que estão escritos por extenso em cópias de Declarações de Imposto de Renda, são exemplos de domínio de conteúdo. A gestão do caso só será completa se for possível tratar, além dos metadados, do conteúdo em si.
 Inicialmente, uma tarefa simples seria a indexação de arquivos para que a equipe do caso possa pesquisar palavras dentro do texto (a construção de um Google do caso). Os arquivos podem estar em diversos formatos (PDF, EML, DOC, TXT…) e então o computador apresentado aí na figura abaixo poderia resolver. Ele é um appliance (junção de hardware e software otimizados para trabalhos específicos) vendido pelo Google para que sua equipe possa ter um Google só dela.
Inicialmente, uma tarefa simples seria a indexação de arquivos para que a equipe do caso possa pesquisar palavras dentro do texto (a construção de um Google do caso). Os arquivos podem estar em diversos formatos (PDF, EML, DOC, TXT…) e então o computador apresentado aí na figura abaixo poderia resolver. Ele é um appliance (junção de hardware e software otimizados para trabalhos específicos) vendido pelo Google para que sua equipe possa ter um Google só dela.
Se o orçamento não for tão alto, um Copernic Desktop Search pode resolver; se os formatos não forem tão variados, até a busca do Microsoft Windows Explorer solucionará a questão.
Mas o estado da arte de uma gestão do conteúdo do caso vai além da busca de palavras-chave. Os softwares específicos para análise jurídica conseguem resumir os documentos, construindo espécies de ementas automáticas; separar conteúdo por pessoas, empresas, locais, valores e datas; identificar tipos de documentos, como ofícios ou sentenças; e ampliar a palavra-chave para termos mais complexos, quando alimentados por ontologias descritivas do contexto do caso concreto.
Uma ressalva importante aqui é a barreira do idioma. O português é simplesmente ignorado pelas soluções que trabalham conteúdo. Esta deficiência aparece mais claramente no reconhecimento de voz, como exemplos: a suíte de ditados Dragon possui uma série de funcionalidades para advogados abandonarem o teclado e passarem a falar seus textos; o assistente pessoal Siri do iPhone permite enviar um e-mail sem a necessidade de sequer encostar no aparelho; o Microsoft Windows responde a comandos de voz. Trata-se de uma questão de mercado e de capacidade de desenvolvimento e domínio tecnológico; afinal, para a construção de uma ementa automática o software deve dominar a sintaxe e a semântica da língua.
Continuando, os softwares de suporte a litígios atuam em diversos momentos da gestão e produção no caso. Na tentativa de descrever a abrangência deste fluxo de trabalho, cito o diagrama do CasePoint, software da empresa @LegalDiscovery:
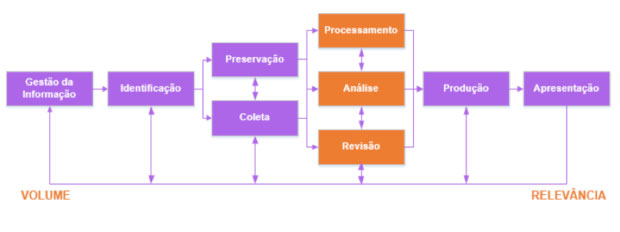
O diagrama descreve diversas etapas que compreendem do volume à da informação. Identificar as necessidades informacionais é pré-condição para preparar a fase de coleta e de guarda do material do caso.
Em laranja, destaquei a fase TAR, que compreende as tecnologias que apoiam a revisão, classificação, indexação e análise dos documentos do caso. É nesse ponto que essa tecnologia mais agrega valor, inclusive utilizando aprendizado de máquina para evoluir conforme o tempo de uso (machine learning é um termo ligado a técnicas de Inteligência Artificial para indicar genericamente que o computador passa a apreender com seus acertos e erros).
Finalmente, existe a fase de produção das peças do caso e a apresentação das conclusões. Como já indicado aqui anteriormente, um resumo visual bem apresentado representa alta concentração de informação e relevância aprimorada.
O diagrama apresentado pela empresa é um detalhamento do ciclo de produção de informação estratégica, o qual pode ser resumido em coleta -> análise -> difusão e é encontrado na literatura em ampliações das mais variadas.
Concordo que o ponto destacado é onde a tecnologia moderna mais se concentra em desenvolver soluções, visto a importância da demanda. A tecnologia da informação possui como atualidade e também como tendência apoiar os serviços jurídicos no campo do conteúdo, ajudando na análise e produção de documentos e peças.